


如何准确且高效地构建三维模型、理解和生成三维世界正成为AGI、AI4S、具身智能三大AI热门领域共同关注的焦点。针对目前三维结构建模方法存在数据表示不统一、建模任务不统一的痛点,近日,深势科技、北京科学智能研究院与北京大学的研究者发表论文,提出了Uni-3DAR,一个通过Next Token Prediction预测任务将三维分子的生成与理解统一起来的框架。相关信息显示,这是国际上首个此类科学大模型。

众所周知,从微观世界的分子与材料结构,到宏观世界的几何与空间智能,三维结构都是物理世界的基石。三维结构在微观(如原子、分子、蛋白质)和宏观(如物体整体、力学结构)层面均表现出显著稀疏性:大部分空间为空白,只有局部区域含有重要信息。传统的全体素网格表示计算资源消耗巨大,无法利用这种稀疏性。
Uni-3DAR的创新之处,在于利用三维结构固有的稀疏性,通过八叉树分解、精细令牌化与二级子树压缩,大幅降低数据表示的复杂度,实现了从微观到宏观三维结构的统一表示,为后续自回归生成与理解任务提供了高效、通用的数据基础。
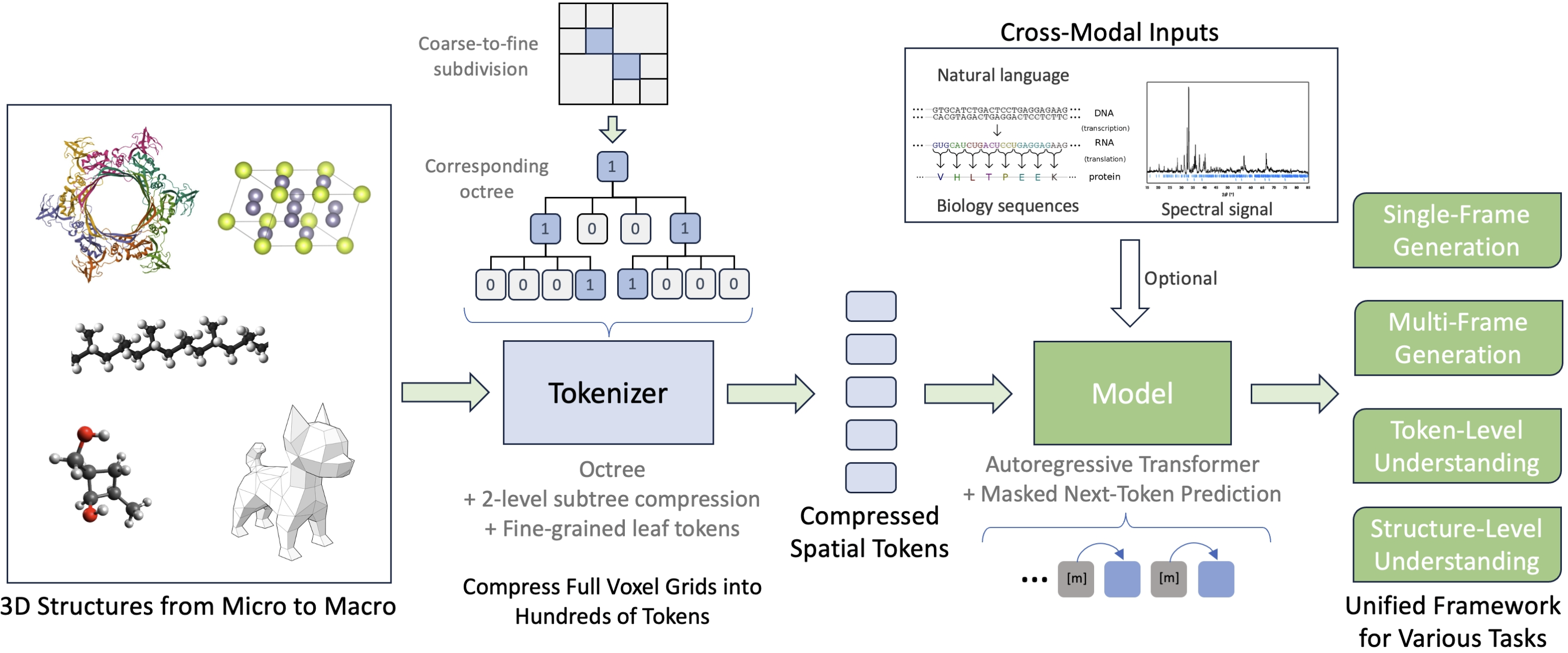
Uni-3DAR 整体架构
深势科技是国内AI for Science领军企业,其AI算法负责人柯国霖在社交平台分享了这篇其参与的自回归模型论文,论文作者中还包括中国科学院院士鄂维南,深势科技创始人兼首席科学家、北京科学智能研究院院长张林峰等。柯国霖表示,Uni-3DAR的核心是一种新颖的层次化词元化(hierarchical tokenization)方法,它能将三维分子转化为一维的词元序列。基于这套词元化方法,Uni-3DAR使用自回归的方式,统一了三维分子的生成和理解任务。其在小分子、晶体、蛋白等任务上,都大幅超过了之前的基于扩散模型的方法,证明了自回归生成在3D任务上的有效性。此模型不仅可以用在微观的三维分子,也可以用到宏观的三维任务上,具备跨尺度的能力。
该论文在微观三维结构领域设计了一系列任务,包括分子生成、晶体结构生成与预测、蛋白结合位点预测、蛋白小分子对接以及基于预训练的分子性质预测。实验结果显示,在生成任务中,Uni-3DAR的性能相较于现有扩散模型实现了高达256%的相对提升,同时推理速度也快了21.8倍,这表明Uni-3DAR不仅能统一不同类型的三维结构数据及任务,而且在效果和速度上均实现了显著提升,充分验证了该框架的有效性与高效性。
目前,Uni-3DAR的实验主要集中在微观结构领域,未来需在宏观三维结构任务中进一步验证其通用性和扩展性。此外,还需融合多种数据类型与任务,构建并联合训练一个更大规模的Uni-3DAR基座模型,以进一步提升性能与泛化能力。同时,Uni-3DAR具备天然的多模态扩展潜力,后续可引入更多模态的信息,例如蛋白质序列、氨基酸组成,甚至结合大语言模型与科学文献知识,共同训练一个具备物理世界理解能力的多模态科学语言模型,从而为构建通用科学智能体打下基础。


